Features
Multi-driver support
Remember the @instance.register? That kicks in now!
The idea behind μMongo is to allow the same document definition to be used with different MongoDB drivers.
To achieve that the user only defines document templates. Templates which will be implemented when registered by an instance:
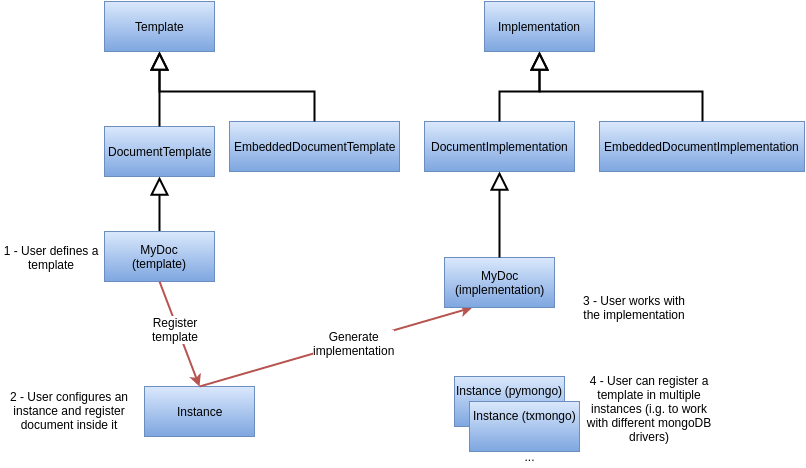
Basically an instance provides three types of information:
- The MongoDB driver to use
- The database to use
- The documents implemented
This way a template can be implemented by multiple instances, this can be useful for example to:
- Store the same documents in different databases
- Define an instance with an async driver for a web server and a synchronous one for shell interactions
But enough of theory, let's create our first instance!
>>> from umongo import Instance >>> import pymongo >>> con = pymongo.MongoClient() >>> instance1 = Instance(con.db1) >>> instance2 = Instance(con.db2)
Now we can define & register documents, then work with them:
>>> class Dog(Document): ... pass >>> Dog # mark as a template in repr <Template class '__main__.Dog'> >>> Dog.is_template True >>> DogInstance1Impl = instance1.register(Dog) >>> DogInstance1Impl # mark as an implementation in repr <Implementation class '__main__.Dog'> >>> DogInstance1Impl.is_template False >>> DogInstance2Impl = instance2.register(Dog) >>> DogInstance1Impl().commit() >>> DogInstance1Impl.count_documents() 1 >>> DogInstance2Impl.count_documents() 0
Note
You can use instance.register as a decoration to replace the template
with its implementation. This is especially useful if you only use a single
instance:
>>> @instance.register ... class Dog(Document): ... pass >>> Dog().commit()
Note
Often in more complex applications you won't have your driver ready when defining your documents. In such cases you should use a special instance with lazy db loader depending on your driver:
>>> from umongo import TxMongoInstance >>> instance = TxMongoInstance() >>> @instance.register ... class Dog(Document): ... pass >>> # Don't try to use Dog (except for inheritance) now ! >>> db = create_txmongo_database() >>> instance.init(db) >>> # Now instance is ready >>> yield Dog().commit()
For the moment all examples have been done with PyMongo, but things are
pretty much the same with other drivers, just configure the instance
and you're good to go:
>>> db = motor.motor_asyncio.AsyncIOMotorClient()['umongo_test'] >>> instance = Instance(db) >>> @instance.register ... class Dog(Document): ... name = fields.StrField(attribute='_id') ... breed = fields.StrField(default="Mongrel")
Of course the way you'll be calling methods will differ:
>>> odwin = Dog(name='Odwin', breed='Labrador') >>> yield from odwin.commit() >>> dogs = yield from Dog.find()
Inheritance
Inheritance inside the same collection is achieve by adding a _cls field
(accessible in the document as cls) in the document stored in MongoDB
>>> @instance.register ... class Parent(Document): ... unique_in_parent = fields.IntField(unique=True) ... class Meta: ... allow_inheritance = True >>> @instance.register ... class Child(Parent): ... unique_in_child = fields.StrField(unique=True) >>> child = Child(unique_in_parent=42, unique_in_child='forty_two') >>> child.cls 'Child' >>> child.dump() {'cls': 'Child', 'unique_in_parent': 42, 'unique_in_child': 'forty_two'} >>> Parent(unique_in_parent=22).dump() {'unique_in_parent': 22} >>> [x.document for x in Parent.opts.indexes] [{'key': SON([('unique_in_parent', 1)]), 'name': 'unique_in_parent_1', 'sparse': True, 'unique': True}]
Warning
You must register a parent before its child inside a given instance.
Indexes
Warning
Indexes must be first submitted to MongoDB. To do so you should call :meth:umongo.Document.ensure_indexes once for each document
In fields, the unique attribute is implicitly handled by an index:
>>> @instance.register ... class WithUniqueEmail(Document): ... email = fields.StrField(unique=True) >>> [x.document for x in WithUniqueEmail.opts.indexes] [{'key': SON([('email', 1)]), 'name': 'email_1', 'sparse': True, 'unique': True}] >>> WithUniqueEmail.ensure_indexes() >>> WithUniqueEmail().commit() >>> WithUniqueEmail().commit() [...] ValidationError: {'email': 'Field value must be unique'}
Note
The index params also depend of the required, and null field attributes
For more custom indexes, the Meta.indexes attribute should be used:
>>> @instance.register ... class CustomIndexes(Document): ... name = fields.StrField() ... age = fields.Int() ... class Meta: ... indexes = ('#name', 'age', ('-age', 'name')) >>> [x.document for x in CustomIndexes.opts.indexes] [{'key': SON([('name', 'hashed')]), 'name': 'name_hashed'}, {'key': SON([('age', 1), ]), 'name': 'age_1'}, {'key': SON([('age', -1), ('name', 1)]), 'name': 'age_-1_name_1'}
Note
Meta.indexes should use the names of the fields as they appear
in database (i.g. given a field nick = StrField(attribute='nk'),
you refer to it in Meta.indexes as nk)
Indexes can be passed as:
- a string with an optional direction prefix (i.g.
"my_field") - a list of string with optional direction prefix for compound indexes
(i.g.
["field1", "-field2"]) - a :class:
pymongo.IndexModelobject - a dict used to instantiate an :class:
pymongo.IndexModelfor custom configuration (i.g.{'key': ['field1', 'field2'], 'expireAfterSeconds': 42})
Allowed direction prefix are:
- + for ascending
- - for descending
- $ for text
- # for hashed
Note
If no direction prefix is passed, ascending is assumed
In case of a field defined in a child document, its index is automatically
compounded with the _cls
>>> @instance.register ... class Parent(Document): ... unique_in_parent = fields.IntField(unique=True) ... class Meta: ... allow_inheritance = True >>> @instance.register ... class Child(Parent): ... unique_in_child = fields.StrField(unique=True) ... class Meta: ... indexes = ['#unique_in_parent'] >>> [x.document for x in Child.opts.indexes] [{'name': 'unique_in_parent_1', 'sparse': True, 'unique': True, 'key': SON([('unique_in_parent', 1)])}, {'name': 'unique_in_parent_hashed__cls_1', 'key': SON([('unique_in_parent', 'hashed'), ('_cls', 1)])}, {'name': '_cls_1', 'key': SON([('_cls', 1)])}, {'name': 'unique_in_child_1__cls_1', 'sparse': True, 'unique': True, 'key': SON([('unique_in_child', 1), ('_cls', 1)])}]
I18n
μMongo provides a simple way to work with i18n (internationalization) through
the :func:umongo.set_gettext, for example to use python's default gettext:
from umongo import set_gettext from gettext import gettext set_gettext(gettext)
This way each error message will be passed to the custom gettext function
in order for it to return the localized version of it.
See examples/flask for a working example of i18n with flask-babel.
Note
To set up i18n inside your app, you should start with messages.pot which is a translation template of all the messages used in μMongo (and its dependency marshmallow).
Marshmallow integration
Under the hood, μMongo heavily uses marshmallow for all of its data validation work.
However an ODM has some special needs (i.g. handling required fields through MongoDB's
unique indexes) that force it to extend marshmallow's base types.
In short, you should not try to use marshmallow base types (:class:marshmallow.Schema,
:class:marshmallow.fields.Field or :class:marshmallow.validate.Validator for instance)
in a μMongo document but instead use their μMongo equivalents (respectively
:class:umongo.abstract.BaseSchema, :class:umongo.abstract.BaseField and
:class:umongo.abstract.BaseValidator).
Now let's go back to the Base concepts, the schema contains a little... simplification !
According to it, the client and OO worlds are made of the same data, but only
in a different form (serialized vs object oriented).
However pretty often the API you want to provide doesn't strictly
follow your datamodel (e.g. you don't want to display or allow modification
of the passwords in your /users route)
Let's go back to our Dog document, in real life you can rename your dog but
not change it breed. So in our user API we should have a schema that enforce this !
>>> DogMaSchema = Dog.schema.as_marshmallow_schema()
As you can imagine, as_marshmallow_schema converts the original μMongo
schema into a pure marshmallow schema. This way we can now customize it
by subclassing it:
>>> class PatchDogSchema(DogMaSchema): ... class Meta: ... fields = ('name', ) >>> patch_dog_schema = PatchDogSchema() >>> patch_dog_schema.load({'name': 'Scruffy', 'breed': 'Golden retriever'}).errors {'_schema': ['Unknown field name breed.']} >>> ret = patch_dog_schema.load({'name': 'Scruffy'}) >>> ret.errors {} >>> ret.data {'name': 'Scruffy'}
Finally we can integrate the validated data into OO world:
>>> my_dog.update(ret.data) >>> my_dog.name 'Scruffy'
Note
When instantiating a custom marshmallow schema, you can usestrict=True
to make the schema raise a ValidationError instead of returning an error dict.
This allows for better integration with μMongo's own error handling:
try: data, _ = patch_dog_schema.load(payload) my_dog.update(data) my_dog.commit() except (ValidationError, UMongoError) as e: # error handling
This works great when you want to add special behavior depending of the situation.
For more simple use cases we could use the
marshmallow pre/post processors.
For example to simply customize the dump:
>>> from umongo import post_dump # same as `from marshmallow import post_dump` >>> @instance.register ... class Dog(Document): ... name = fields.StrField(required=True) ... breed = fields.StrField(default="Mongrel") ... birthday = fields.DateTimeField() ... @post_dump ... def customize_dump(self, data): ... data['name'] = data['name'].capitalize() ... data['brief'] = "Hi ! My name is %s and I'm a %s" % (data['name'], data['breed'])" ... >>> Dog(name='scruffy').dump() {'name': 'Scruffy', 'breed': 'Mongrel', 'brief': "Hi ! My name is Scruffy and I'm a Mongrel"}
Now let's imagine we want to allow the per-breed creation of a massive number of ducks. The API would accept a really different format than our datamodel:
{ 'breeds': [ {'name': 'Mandarin Duck', 'births': ['2016-08-29T00:00:00', '2016-08-31T00:00:00', ...]}, {'name': 'Mallard', 'births': ['2016-08-27T00:00:00', ...]}, ... ] }
Now starting from the μMongo schema would not help, so we will create our schema from scratch... almost:
>>> MassiveBreedSchema(marshmallow.Schema): ... name = Duck.schema.fields['breed'].as_marshmallow_field() ... births = marshmallow.fields.List( ... Duck.schema.fields['birthday'].as_marshmallow_field()) >>> MassiveDuckSchema(marshmallow.Schema): ... breeds = marshmallow.fields.List(marshmallow.fields.Nested(MassiveBreedSchema))
Note
A custom marshmallow schema :class:umongo.marshmallow_bonus.SchemaFromUmongo
can be used instead of regular :class:marshmallow.Schema to benefit from a tighter
integration with μMongo (unknown field checking and field with missing value
actually return the missing singleton instead of serializing it as None)
This time we directly convert μMongo schema's fields into their marshmallow
equivalent with as_marshmallow_field. Now we can build our ducks easily:
try: data, _ = MassiveDuckSchema(strict=True).load(payload) ducks = [] for breed in data['breeds']: for birthday in breed['births']: duck = Duck(breed=breed['name']), birthday=birthday) duck.commit() ducks.append(duck) except ValidationError as e: # Error handling ...
One final thought
A field's missing and default attributes are not handled the same in
marshmallow and μMongo.
In marshmallow default contains the value to use during serialization
(i.e. calling schema.dump(doc)) and missing the value for deserialization.
where the field is
In μMongo however there is only a default attribute which will be used when
creating (or loading from user world) a document where this field is missing.
This is because you don't need to control how μMongo will store the document in
mongo world.
So when you use as_marshmallow_field, the resulting marshmallow field's
missing&default will by default both be inferred from μMongo's
default field. You may want to overwrite this behavior by using
marshmallow_missing/marshmallow_default attributes:
@instance.register class Employee(Document): name = fields.StrField(default='John Doe') birthday = fields.DateTimeField(marshmallow_missing='2000-01-01T00:00:00Z') # You can use `missing` singleton to overwrite `default` field inference skill = fields.StrField(default='Dummy', marshmallow_default=missing) ret = Employee.schema.as_marshmallow_schema()().load({}) assert ret.data == {'name': 'John Doe', 'birthday': datetime(2000, 1, 1, 0, 0, tzinfo=tzutc()), 'skill': 'Dummy'} ret = Employee.schema.as_marshmallow_schema()().dump({}) assert ret.data == {'name': 'John Doe', 'birthday': '2000-01-01T00:00:00+00:00'} # Note `skill` hasn't been serialized
Field validate & io_validate
Fields can be configured with special validators through the validate attribute:
from umongo import Document, fields, validate @instance.register class Employee(Document): name = fields.StrField(validate=[validate.Length(max=120), validate.Regexp(r"[a-zA-Z ']+")]) age = fields.IntField(validate=validate.Range(min=18, max=65)) email = fields.StrField(validate=validate.Email()) type = fields.StrField(validate=validate.OneOf(['private', 'sergeant', 'general']))
Those validators will be enforced each time a field is modified:
>>> john = Employee(name='John Rambo') >>> john.age = 99 # it's not his war anymore... [...] ValidationError: ['Must be between 18 and 65.']
Now sometimes you'll need for your validator to query your database (this
is mainly done to validate a :class:umongo.data_objects.Reference). For
this need you can use the io_validate attribute.
This attribute should be passed a function (or a list of functions) that
will do database access in accordance with the used mongodb driver.
For example with Motor-asyncio driver, io_validate's functions will be
wrapped by :class:asyncio.coroutine and called with yield from.
from motor.motor_asyncio import AsyncIOMotorClient db = AsyncIOMotorClient().test instance = Instance(db) @instance.register class TrendyActivity(Document): name = fields.StrField() @instance.register class Job(Document): def _is_dream_job(field, value): if not (yield from TrendyActivity.find_one(name=value)): raise ValidationError("No way I'm doing this !") activity = fields.StrField(io_validate=_is_dream_job) @asyncio.coroutine def run(): yield from TrendyActivity(name='Pythoning').commit() yield from Job(activity='Pythoning').commit() yield from Job(activity='Javascripting...').commit() # raises ValidationError: {'activity': ["No way I'm doing this !"]}
Warning
When converting to marshmallow with as_marshmallow_schema and
as_marshmallow_fields, the io_validate attribute will not be preserved.